
(通讯员网轩)近日,武汉大学国家网络安全学院任延珍教授课题组的研究成果被第46届IEEE安全和隐私会议(The46th IEEE Symposium on Security and Privacy,简称IEEES&P)录用,会议将于2025年5月12日至15日在美国旧金山举行。
论文题目为“Lombard-VLD: Voice Liveness Detection based on Human Auditory Feedback”(基于人类听觉反馈的声音活体检测方法),由任延珍教授和何琨副教授共同指导完成。武汉大学为第一完成单位,任延珍和何琨为共同通信作者,国家网络安全学院2021级硕士生朱洪承和2020级博士生孙宗锟为共同第一作者,武汉大学国家多媒体软件工程技术研究中心杨玉红副教授,涂卫平教授,国家网络安全学院2022级博士生刘武洋、2024级硕士生王子煊和2023级硕士生鄢湧棚参与了该成果的研究工作。
近年来,说话人认证系统(ASV,Audio SpeakerVerification)被广泛应用于银行、零售、金融、司法取证和语音交互等多种重要领域,用于进行用户的身份认证。然而,ASV极易受到重放攻击、语音合成、语音对抗样本等语音欺骗技术的攻击。声音活体检测技术(VLD,Voice Liveness Detection)旨在鉴别语音是来自真实说话人或是扬声器,以防止ASV系统被伪造语音欺骗。
现有主流VLD方法主要通过对说话人和扬声器在声学或其他传感器所采集信号层面上的差异性来进行活体检测。本文首次提出基于人类听觉反馈机制的声音活体检测方法(Lombard-VLD),该方法在进行真实说话人检测的关键性特征在于真实的人具有Lombard效应,而现有的语音欺骗算法不具备这类条件反射效应。Lombard效应是指说话人在嘈杂的声场背景中会自动调整说话模式,如提高音量、改变说话的模式,以确保对方可以听清其声音。针对该现象,本文提出了基于差分网络SE-ResBlock的声音活体检测方案Lombard-VLD(如图1所示),用于捕捉真实说话人和语音欺骗算法在Lombard效应激励情况下所产生语音信号的声学差异特征,实现说话人活体检测。综合实验结果表明,该论文所提出的方法具备良好的检测准确率、鲁棒性和泛化性。该方法在两个主流语音数据集上的检测错误率分别为0%和0.24%,优于目前最先进的VLD方法;该方法对多种环境因素,如不同的距离、说话者的姿势和环境噪声等,具有良好的鲁棒性,平均检测错误率低于1.49%;对于未见过的说话者、性别和语音数据集均具有良好的泛化性,检测错误率分别低于2.68%、3.44%和7.32%。
该项成果为声音活体检测领域提供了新的实用性解决方案。尤其在目前各种音视频合成技术越来越逼真的情况下,仅从信号层面进行真伪检测越来越困难,而从真实的活体人所具备的一些自然条件反射角度进行人脸或语音的伪造检测将会成为后期进行深度伪造检测的一类有效途径,为防止人工智能生成技术所带来的AI欺诈问题提供了新的解决思路。
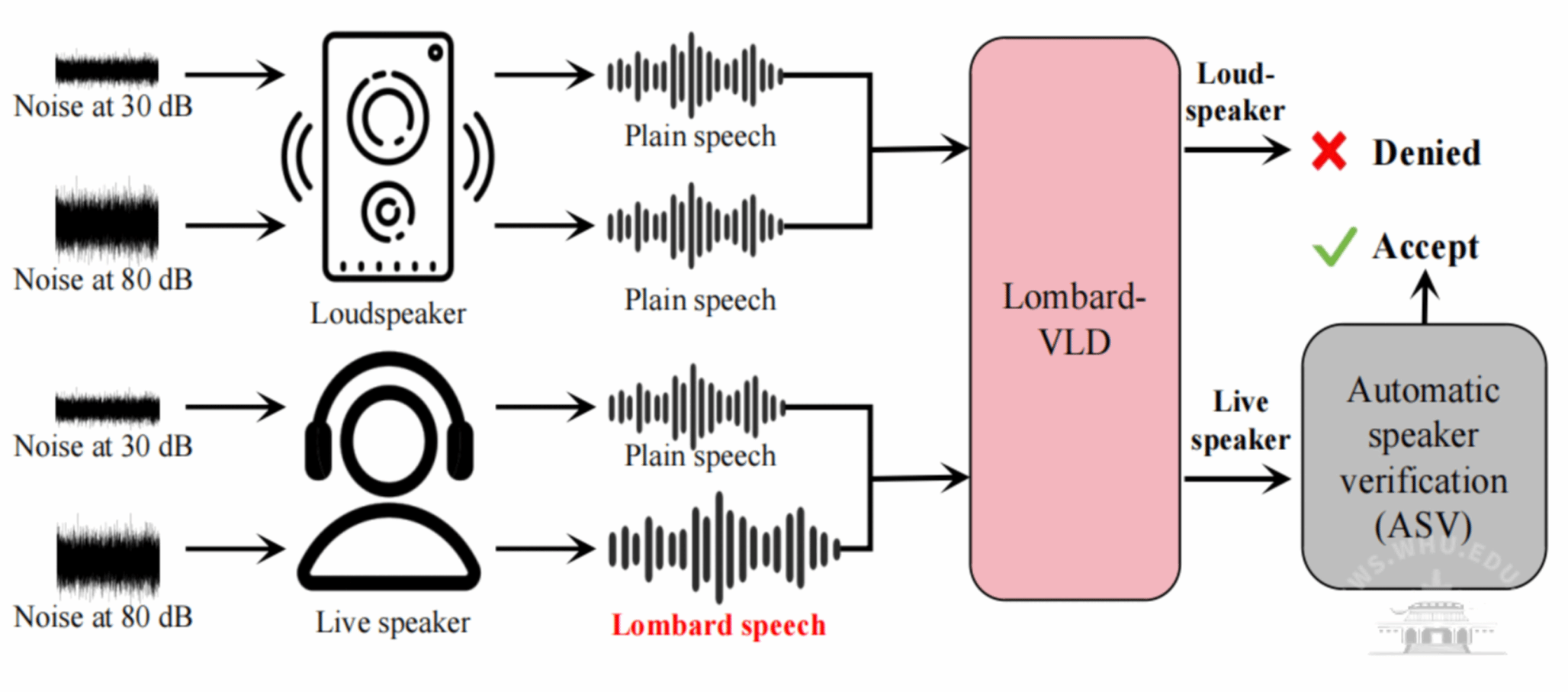
图1Lombard-VLD:提取Lombard和普通语音间的特征差异实现活体检测
据悉,IEEE Symposium on Security & Privacy国际会议创办于1980年,是信息安全领域最具影响力的旗舰会议,是信息安全领域公认的四大顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。IEEES&P2025录用率为14.8%,被录用的稿件反映了信息安全领域国际最前沿的研究水平。
(编辑:相茹)
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。
相关文章



暂无评论...